
5 Lessons Learned Exploring Agentic Engineering
And 2 Agentic Workflow Projects

You heard it right folks!
The latest buzzword is upon us. Not mere context engineering. Agentic engineering.
Back in December, I was playing around with Ollama and the Gemini API, trying to create an agent capable of running a text-based adventure game, similar to DND. I eventually gave up, as state management proved to be far too hard for Ollama, and even too hard for Gemini 2.0-flash. I eventually gave up on creating a working DND simulator, and settled instead for a simple counter, along with a narrator explaining the user’s updates to it.
My conclusion at the end of that adventure was that:
“Asking an LLM to update state makes about as much sense as asking James Joyce to file your taxes.“
Well, in the months since then, I’ve eaten my tongue. Claude Code, OpenClaw, and the slew of agentic programs which have sprung up in the last few months have collectively blown the tech industry out of the water. Now everyone on LinkedIn is asking for people with “1-2 years of agentic engineering experience”. I first usedClaude Code in the middle of February, to finish the build-out of my BetaZero UI. The speed, volume, and coding ability was worlds above anything I’d previously experienced from an agentic coding tool.
So, with that in mind…
Project 1. James Joyce, Tax Assistant
https://github.com/EvanMcCormick37/mvp-james-joyce
This is the first of the three projects I’ll talk about. I built this in 2 days as my round 3 interview for an internship at a Denver company (I went through all four rounds, but unfortunately did not land the internship).
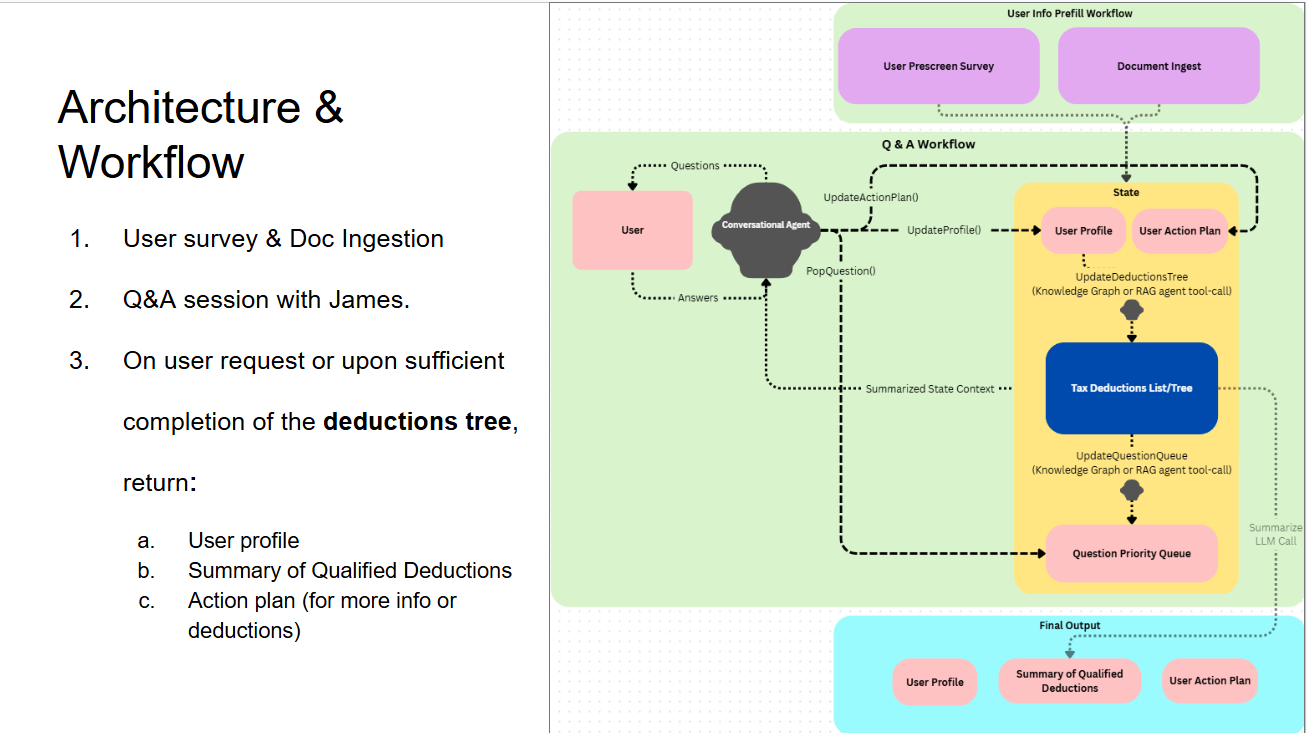
It took me about an hour to come up with the initial concept. An agent which walks you through your tax situation and helpfully lists the deductions you are likely to qualify for, all while building an action plan to help you get the maximum possible tax deductions.
Lesson 1: Iterate Quickly, Test Manually
When I first had the idea of the application, the workflow looked completely different from the diagram above. I initially envisioned the model as an agentic Graph-RAG question-answering system which used a knowledge-graph and vector database built from the current year’s official IRS Publications. I imagined that the user would ask a question, the model would provide a grounded-and-sourced answer, along with 1-2 pertinent questions for the user which would help determine their eligibility status for deductions.
I gave my specifications (in a bit more detail) to Claude, and had it draft an architecture document for an MVP. I looked it over, made some tweaks, then sent it on to Claude Code and asked it to code up an MVP implementation. The whole process took less than two hours, and the actual coding implementation was done in 30 minutes.
But when I actually used the application, something felt off…
The problem was the Q&A workflow. Every user statement and question was answered with a wall of text, along with a single question at the end asking them about some random aspect of their financial history. This was not an elegant conversation, or a time-saving application. As it turns out, the architecture which works in a standard RAG document-answering application doesn’t work at all in this use case.
So I tried something else. I just had a conversation with Gemini about my possible deductions, and imagined how I could improve upon the experience.
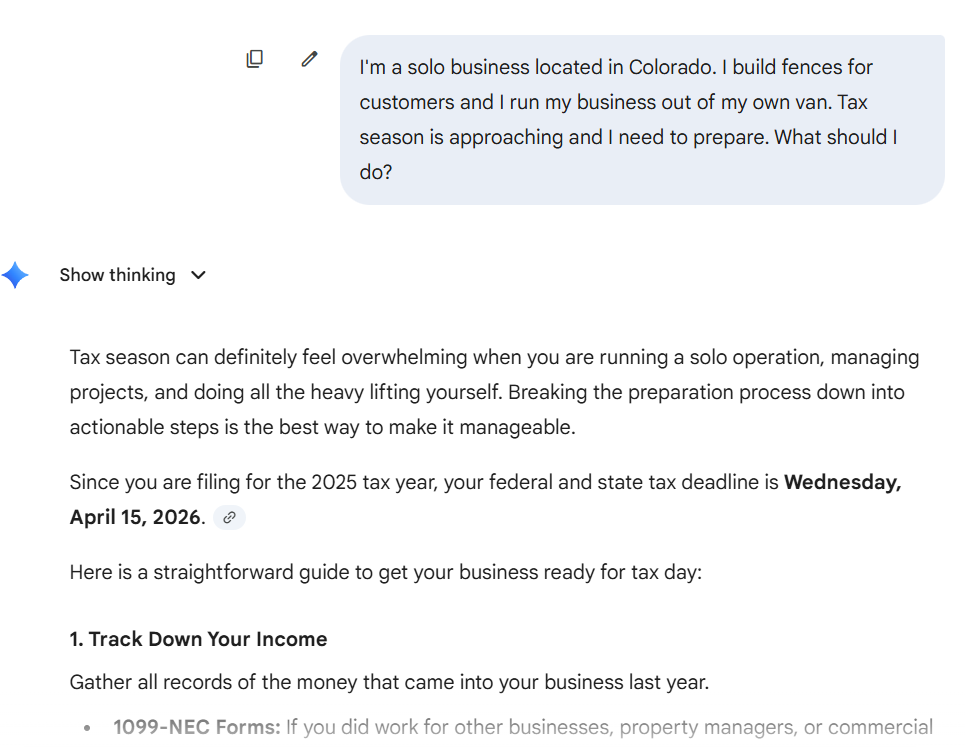
The strength of Gemini was its’ conversationality. It answered every question clearly, gave me avenues to explore, and never felt like it was forcing a topic on me. That is the strength of a conversational agentic application.
I reworked the design to optimize the conversational flow rather than the data organization. I simplified the context engineering vastly: Rather than an entire Graph-RAG system, I converted the IRS Guidelines for Individual Deductions into a single YAML file which was ingested as context in the system prompt. The model used tool-calling to update three output files: user-profile.yaml, deductions-tree.yaml, and action-plan.yaml. Instead of trying to answer user questions with endless citations, I told the model to focus on asking the right questions: I had it treat the conversation as a game of “20 questions”, trying to determine the user’s eligibility for all deductions in as few conversational turns as possible.
Lesson 2: Don’t use two Agents when you can use one.
This one should be pretty self-explanatory. When I was designing the application’s architecture, I initially considered using one agent to hold a conversation with the user, and another to update state. Meanwhile, determining the user’s eligibility for tax deductions would either be done using an agentic graph-RAG + reasoning model, or a “Tax Engine” (A DAG in which each node consists of a calculation or decision. Think those “Who’s your male celebrity crush?” personality quizzes they used to print on magazines, except the question is (“which tax deductions do you qualify for?”). But here’s the kicker: multiple agents means multiple “contexts”. How much of the conversation must the “state-updater” agent know in order to update state correctly? Does its context remain the same every time, or is it modified with each function call? How do the agents “communicate” with each other? Do they start conversations, or do they use “message” functions to message each other?
The more agents you have running around your program, the more room there is for miscommunication, confusion, and ultimately failure. Funny enough, this is also a good maxim when designing a deterministic system: One monolith service container is often a much more elegant and easy to implement solution than 10 microservices all communicating back and forth via shoestring attached to tin-cans.
Lesson 3: Respect the KV-Cache.
When I was initially building the application, I was struggling with determining how to feed the current state of the application (recall: user-profile.yaml, deductions-tree.yaml, action-plan.yaml). Our tax assistant must know the current state of the application to ask the user the “optimal” question (i.e. the one which resolved the most unresolved tax deductions). But how should we feed that state to it? If we just keep feeding in new state along with every user answer, we start filling up the context window with “ghosts” of old state. We really need a way for the model to recognize the current state of the application, and just the current state. My original idea was as simple as it was naive: Just feed the state back into the system prompt!
This was a blunder.
LLMs have a feature called the KV Cache. It saves previously computed inference values associated with all of the text which was previously generated. So at each generation step, the model is only computing the associations of the last previously generated token. This means that 1) The model is significantly cheaper to run, 2) it scales linearly rather than quadratically (especially useful for long context windows) and 3) YOU SHOULD ABSOLUTELY NEVER IN ANY CIRCUMSTANCE UPDATE THE TOKENS LOCATED AT THE BEGINNING OF THE CONTEXT WINDOW.
If you do choose to edit the context at the beginning of the model’s context window, you force it to re-compute the KV-pairs for every single token which succeeds your edit. This, to put it bluntly, is expensive.
The first time I ran the 2nd, “improved” implementation of James Joyce, I ran up a $1.50 on the Anthropic API for a 20-turn conversation.
The solution I eventually went with was to inject the current state as the precursor to the user’s current question, and to strip the stale state from the user’s prior question with each new conversational step. If I were to go back and improve this project, I would try just keeping each state-view present in the user queries.
Project 2: Scáthach Agentic Tutor
https://github.com/EvanMcCormick37/scathach-tutor
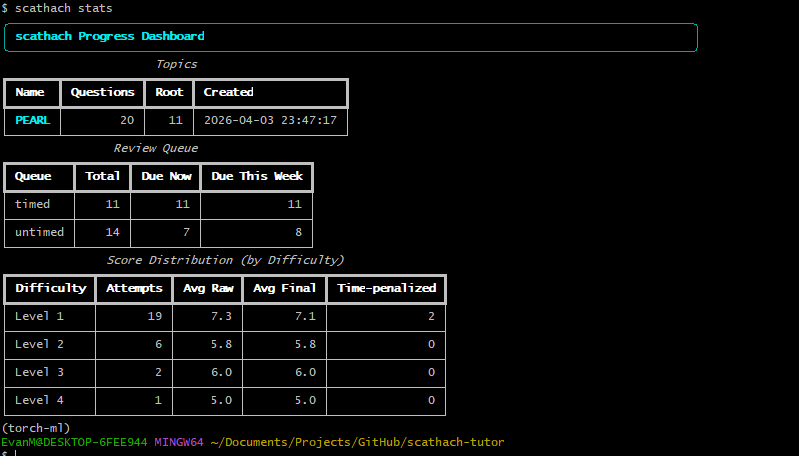
This one was a little closer to home. I’ve read a lot this past year: research reports, individual articles, research papers, blog posts, etc. However, I often fear that I haven’t really learned from what I’ve read, or that the knowledge has faded in the months since I last seriously worked on it.
LLMs help me develop and test my understanding of papers I’ve read. They allow me to immediately have a conversation with a knowledgeable person on the topic being covered. They can also create quizzes which allow me to test my understanding of a topic on a surprisingly deep level. But I want these conversations to stick with me.
To fix this problem, I built Scathach. It’s essentially the “read article —> answer short quiz about said article” workflow wrapped into a Python package. In addition to the basic quizzing functionality, it stores all previously answered questions in a database equipped with the FSRS algorithm, so that as more documents are ingested into the system, the user can selectively review the documents which they struggle the most with. It’s currently available as a Python package you can install in your local python environment.
Lesson 4: Watch out for Scope Creep.
When iterating on Scathach and James Joyce, I initially built the MVP with a React front-end + REST API + FastAPI backend. Why not? It only took 15 minutes to code up the whole thing anyways.
It turns out that even with agentic coding tools, scope creep is very real. Refactoring is often trickier than the initial build-out, and when you’re vibe co— sorry, "agentic engineering", you won’t have a deep understanding of your architecture right at the outset.
I quickly found that I preferred developing both of these applications without a ‘full-stack’ architecture. When I begun designing and building these applications, I had a rough idea of what I wanted and what the use cases were, but I didn’t have a clear vision of what the workflow would be. I found this simple design cycle to be incredibly powerful at rapidly iterating and improving upon the product design:
Design → Implement → Test Manually
Once I’m satisfied with the workflow on scathach1, I will probably build it into an executable or cloud application. However, for now I’m content to keep on iterating with my nifty little python module.
Lesson 5: Domain Knowledge will always be important
So… I actually tried to build out Scathach into an executable. Rather, I asked Claude Code to build out Scathach into an executable. I wanted to port it into a format in which my dad (who is not super tech-savvy) could use it. It built out a whole front-end and API, compiled the backend into a binary file, and used a rust library to built it all out into a single .exe file which could be installed on the user’s computer.
Now, do I know anything about Rust, Tauri, or compiling an application into a binary .exe file? Nope. But Claude does, so it should be no problem. And, well, it might have been no problem, had I experience in these things.
What actually happened was I spent an hour trying to work out why the npm build scripts weren’t working, then finding and formatting Icons for the Tauri binary file, and finally installing the .exe without a hitch… only for the installed program to fail to open.
Now, I’m sure I just made some beginner mistake. Someone with more experience in Tauri+Rust binary compilation would fix it in a heartbeat. And I’m sure that if you gave that person access to Claude Code, they’d build a version of the application that is 10x better, and they’d complain about not having built it themselves. But in a way, they did. Even when relying on “expert agents”…
…human expertise still matters.
That’s another reason why I’m keeping this application as a python script for now. I can continue to update it intelligently as long as I understand it.
It’s sad to see people abandoning human expertise for “agentic intelligence”. I feel like society is heading towards the comic dystopias of Idiocracy and Wall-E. But even in the age of intelligent AI systems, the old Data Science adage applies: Garbage In, Garbage Out.
That’s all for now, folks! If you want to try out scathach, just follow the installation instructions on the README.
I’m happy enough with the current version to release it now, but I’m likely going to modify the FSRS implementation, as I’m interested in expanding the concept of spaced repetition to “semantic concepts” rather than “specific questions”.